


Hey Habr.
I recently about what parameters we in the team most often use for Kafka Producer and Consumer in order to get closer to guaranteed delivery. In this article, I want to tell you how we organized the re-processing of an event received from Kafka as a result of a temporary unavailability of an external system.
Modern applications operate in a very complex environment. Business logic wrapped in a modern technology stack, running in a Docker image managed by an orchestrator like Kubernetes or OpenShift, and communicating with other applications or enterprise solutions through a chain of physical and virtual routers. In such an environment, something can always break, so re-processing events in case one of the external systems is unavailable is an important part of our business processes.
How it was before Kafka
Earlier in the project, we used IBM MQ for asynchronous message delivery. If any error occurred during the operation of the service, the received message could be placed in a dead-letter-queue (DLQ) for further manual parsing. The DLQ was created next to the incoming queue, the message transfer took place inside IBM MQ.
If the error was transient and we could detect it (for example, a ResourceAccessException on an HTTP call, or a MongoTimeoutException on a MongoDb query), then the retry strategy took effect. Regardless of the branching of the application logic, the original message was transferred either to the system queue for delayed sending, or to a separate application that was made a long time ago to resend messages. In this case, the retransmission number is written in the header of the message, which is tied to the delay interval or to the end of the policy at the application level. If we have reached the end of the strategy, but the external system is still not available, then the message will be placed in the DLQ for manual parsing.
Search Solutions
, one can find the following . In short, it is proposed to create a topic for each delay interval and implement Consumers on the application side, which will read messages with the required delay.
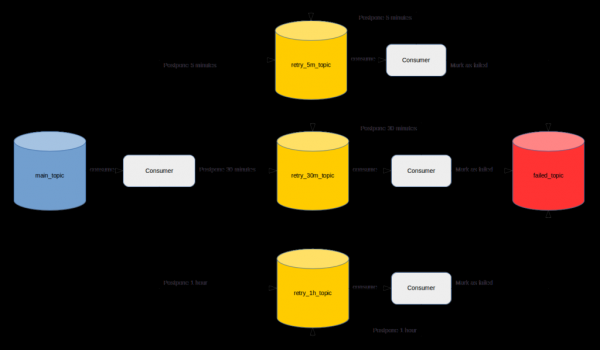
Despite the large number of positive reviews, it seems to me not entirely successful. First of all, because the developer, in addition to implementing business requirements, will have to spend a lot of time implementing the described mechanism.
In addition, if access control is enabled on the Kafka cluster, then you will have to spend some time setting up topics and providing the necessary access to them. In addition to this, you will need to select the correct retention.ms parameter for each of the retry topics so that the messages have time to re-send and not disappear from it. The implementation and request of accesses will have to be repeated for each existing or new service.
Let's now see what mechanisms for reprocessing a message provide us with spring in general and spring-kafka in particular. Spring-kafka has a transitive dependency on spring-retry which provides abstractions for managing different BackOffPolicies. This is a fairly flexible tool, but its significant drawback is that it stores messages for resubmission in the application's memory. This means that restarting the application due to an update or an in-service error will result in the loss of all messages pending reprocessing. Since this item is critical for our system, we did not consider it further.
spring-kafka itself provides several implementations of ContainerAwareErrorHandler like , with which you can, without shifting offset in case of an error, process the message later. Starting with spring-kafka 2.3, it became possible to set BackOffPolicy.
This approach allows reprocessed messages to survive application restart, but the DLQ mechanism is still missing. It was this option that we chose at the beginning of 2019, optimistically believing that DLQ would not be needed (we were lucky and we really didn’t need it after several months of running an application with such a reprocessing system). Temporary errors caused the SeekToCurrentErrorHandler to fire. The remaining errors were printed to the log, led to offset offset, and processing continued with the next message.
Final decision
The implementation based on SeekToCurrentErrorHandler prompted us to develop our own mechanism for resending messages.
First of all, we wanted to use the existing experience and expand it depending on the application logic. For a linear logic application, it would be optimal to stop reading new messages within a short period of time, set as part of the retry strategy. For other applications, I wanted to have a single point that would ensure the execution of the re-call strategy. In addition, this single point must have DLQ functionality for both approaches.
The retry strategy itself must be stored in the application, which is responsible for getting the next interval when a transient error occurs.
Stopping a Consumer for a Linear Application
When working with spring-kafka, the code to stop a Consumer might look something like this:
public void pauseListenerContainer(MessageListenerContainer listenerContainer,
Instant retryAt) {
if (nonNull(retryAt) && listenerContainer.isRunning()) {
listenerContainer.stop();
taskScheduler.schedule(() -> listenerContainer.start(), retryAt);
return;
}
// to DLQ
}In the example, retryAt is the time to restart the MessageListenerContainer if it is still running. The restart will occur in a separate thread running in the TaskScheduler, the implementation of which is also provided by spring.
We find the value of retryAt in the following way:
- The value of the counter of repeated calls is looked up.
- According to the value of the counter, the current delay interval in the retry strategy is searched. The strategy is declared in the application itself; we chose the JSON format to store it.
- The interval found in the JSON array contains the number of seconds after which it will be necessary to repeat the processing. This number of seconds is added to the current time to form the value for retryAt.
- If no interval is found, then retryAt is null and the message is sent to the DLQ for manual parsing.
With this approach, it remains only to store the number of retries for each message that is currently being processed, for example, in the application's memory. Keeping the attempt counter in memory is not critical to this approach, since a linear logic application cannot do the processing as a whole. Unlike spring-retry, restarting the application will not lose all messages for reprocessing, but simply restart the strategy.
This approach helps to take the load off an external system that may be unavailable due to a very heavy load. In other words, in addition to reprocessing, we have achieved the implementation of the pattern .
In our case, the error threshold is only 1, and to minimize system downtime due to a temporary network outage, we use a very granular retry strategy with low latency intervals. This may not be suitable for all group applications, so the relationship between the error threshold and the value of the interval must be selected based on the characteristics of the system.
Separate application for processing messages from applications with non-deterministic logic
Here is an example of code that sends a message to such an application (Retryer), which will resubmit to the DESTINATION topic when the RETRY_AT time is reached:
public <K, V> void retry(ConsumerRecord<K, V> record, String retryToTopic,
Instant retryAt, String counter, String groupId, Exception e) {
Headers headers = ofNullable(record.headers()).orElse(new RecordHeaders());
List<Header> arrayOfHeaders =
new ArrayList<>(Arrays.asList(headers.toArray()));
updateHeader(arrayOfHeaders, GROUP_ID, groupId::getBytes);
updateHeader(arrayOfHeaders, DESTINATION, retryToTopic::getBytes);
updateHeader(arrayOfHeaders, ORIGINAL_PARTITION,
() -> Integer.toString(record.partition()).getBytes());
if (nonNull(retryAt)) {
updateHeader(arrayOfHeaders, COUNTER, counter::getBytes);
updateHeader(arrayOfHeaders, SEND_TO, "retry"::getBytes);
updateHeader(arrayOfHeaders, RETRY_AT, retryAt.toString()::getBytes);
} else {
updateHeader(arrayOfHeaders, REASON,
ExceptionUtils.getStackTrace(e)::getBytes);
updateHeader(arrayOfHeaders, SEND_TO, "backout"::getBytes);
}
ProducerRecord<K, V> messageToSend =
new ProducerRecord<>(retryTopic, null, null, record.key(), record.value(), arrayOfHeaders);
kafkaTemplate.send(messageToSend);
}The example shows that a lot of information is transmitted in headers. The RETRY_AT value is found in the same way as for the consumer'a stop-retry mechanism. In addition to DESTINATION and RETRY_AT, we pass:
- GROUP_ID, by which we group messages for manual analysis and easier search.
- ORIGINAL_PARTITION to try and keep the same Consumer for re-parsing. This parameter can be null, in which case the new partition will be obtained from the record.key() of the original message.
- Updated COUNTER value to follow the retry strategy.
- SEND_TO is a constant indicating whether to send the message for reprocessing when RETRY_AT is reached or to place it in the DLQ.
- REASON - the reason why message processing was interrupted.
Retryer stores messages for resubmission and manual parsing in PostgreSQL. The timer starts a task that finds messages with RETRY_AT and sends them back to the ORIGINAL_PARTITION of the DESTINATION topic with the record.key() key.
Once sent, the messages are removed from PostgreSQL. Manual parsing of messages takes place in a simple UI that interacts with Retryer via the REST API. Its main features are resending or deleting messages from the DLQ, viewing error information, and searching for messages, for example, by error name.
Since access control is enabled on our clusters, we need to additionally request access to the topic that Retryer is listening on, and allow Retryer to write to the DESTINATION topic. This is inconvenient, but, unlike the interval topic approach, we have a full-fledged DLQ and UI to manage it.
There are cases when an incoming topic is read by several different consumer groups whose applications implement different logic. Reprocessing a message through Retryer for one of these applications will result in a duplicate on another. To protect against this, we start a separate topic for re-processing. The incoming and retry topics can be read by the same Consumer without any restrictions.
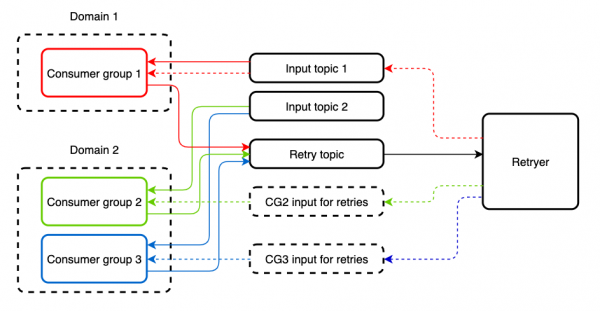
By default, this approach does not provide circuit breaker functionality, but it can be added to an application using or new , by wrapping external service call sites in appropriate abstractions. In addition, it becomes possible to choose a strategy for patterns, which can also be useful. For example, in spring-cloud-netflix this could be a thread pool or a semaphore.
Final World
As a result, we got a separate application that allows you to repeat the processing of a message when an external system is temporarily unavailable.
One of the main advantages of the application is that it can be used by external systems running on the same Kafka cluster without significant modifications on their side! Such an application would only need to access the retry topic, populate a few Kafka headers, and send a message to the Retryer. No additional infrastructure needs to be raised. And in order to reduce the number of messages transferred from the application to the Retryer and vice versa, we singled out applications with linear logic and reprocessed them through the Consumer stop.
Source: habr.com
