

Процесс обновления для вашего Kubernetes-кластера
В какой-то момент при использовании кластера Kubernetes возникает потребность в обновлении работающих нод. Оно может включать в себя обновления пакетов, обновление ядра или развертывание новых образов виртуальных машин. В терминологии Kubernetes это называется .
Этот пост является частью цикла из 4 постов:
- Этот пост.
- Корректное завершение работы pod’ов в Kubernetes-кластере
- Отложенное завершение pod’а при его удалении
- Как избежать простоя в работе Kubernetes-кластера при помощи PodDisruptionBudgets
(прим. пер. переводы остальных статей цикла ожидайте в ближайшее время)
В этой статье мы будем описывать все инструменты, которые предоставляет Kubernetes для достижения нулевого времени простоя для работающих в вашем кластере нод.
Определение проблемы
Поначалу мы будем использовать наивный подход, определять проблемы и оценивать потенциальные риски данного подхода и накапливать знания для решения каждой из проблем, с которыми встретимся на протяжении всего цикла. В результате мы получим конфигурацию, в которой используются lifecycle hooks, readiness probes и Pod disruption budgets для достижения нашего нулевого времени простоя.
Чтобы начать наш путь, давайте возьмем конкретный пример. Допустим, у нас есть кластер Kubernetes из двух нод, в котором запущено приложение с двумя pod’aми, находящимися за Service:
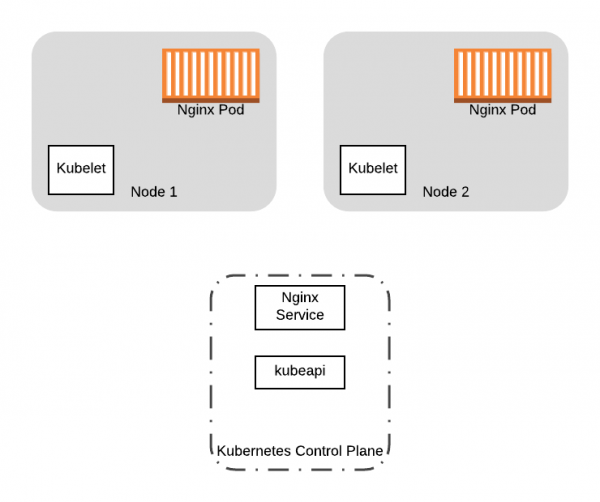
Начнем с двух pod’ов с Nginx и Service запущенных на наших двух нодах Kubernetes-кластера.
Мы хотим обновить версию ядра двух рабочих нод в нашем кластере. Как мы это сделаем? Простым решением было бы загрузить новые ноды с обновленной конфигурацией и затем выключить старые ноды, одновременно с запуском новых. Хотя это сработает, будет несколько проблем с таким подходом:
- Когда вы выключите старые ноды, то запущенные на них pod’ы так же будут выключены. Что если pod’ы нужно очистить для корректного отключения? Система виртуализации, которую вы используете, может не дождаться окончания процесса очистки.
- Что если вы отключите все ноды одновременно? Вы получите приличный простой пока pod’ы переедут на новые ноды.
Нам нужен способ корректной миграции pod’ов со старых нод и при этом нужно быть уверенными, что ни один из наших рабочих процессов не запущен, пока мы вносим изменения для ноды. Или когда мы делаем полную замену кластера, как в примере(то есть заменяем образы VM), мы хотим перенести работающие приложения со старых нод на новые. В обоих случаях мы хотим предотвратить планирование новых pod’ов на старых нодах, а затем выселить с них все запущенные pod’ы. Для достижения этих целей мы можем использовать команду kubectl drain.
Перераспределение всех pod’ов с ноды
Операция drain позволяет перераспределить все pod’ы с ноды. В процессе выполнения drain нода помечается как unschedulable (флаг NoSchedule). Это предотвращает появление на ней новых pod’ов. Затем drain начинает выселять pod’ы с ноды, завершает работу контейнеров, которые на данный момент запущены на ноде отправляя сигнал TERM контейнерам в pod’е.
Хотя kubectl drain отлично справится с выселением pod’ов, есть ещё два фактора, которые могут стать причиной сбоя при выполнении операции drain:
- Ваше приложение должно уметь корректно завершаться при подаче
TERMсигнала. Когда pod’ы выселяются, Kubernetes отправляет сигналTERMконтейнерам и ждет их остановки заданное количество времени, после чего, если они не остановились, завершает их принудительно. В любом случае, если Ваш контейнер не воспримет сигнал корректно, вы все ещё можете потушить pod’ы некорректно, если они в данный конкретный момент работают (например, выполняется транзакция в БД). - Вы теряете все pod’ы, в которых содержится ваше приложение. Оно может быть недоступно на момент запуска новых контейнеров на новых нодах или, если ваши pod’ы развернуты без контроллеров, они могут не перезапуститься в принципе.
Избегаем простоя
Что бы минимизировать время простоя от voluntary disruption, как, например, от операции drain для ноды, Kubernetes предоставляет следующие варианты обработки сбоев:
В остальных частях цикла мы будем использовать данные функции Kubernetes для смягчения последствий переноса pod’ов. Чтобы было легче проследить основную мысль, мы будем использовать наш пример выше со следующей ресурсной конфигурацией:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.15
ports:
- containerPort: 80
---
kind: Service
apiVersion: v1
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
targetPort: 80
port: 80Эта конфигурация является минимальным примером Deployment, который управляет pod’ами nginx в кластере. Кроме того, конфигурация описывает ресурс Service, который можно использовать для доступа к pod’ам nginx в кластере.
На протяжении всего цикла мы будем итеративно расширять данную конфигурацию, чтобы в финале она включала в себя все возможности, предоставляемые Kubernetes для уменьшения времени простоя.
Чтобы получить полностью внедренную и протестированную версию обновлений кластера Kubernetes для нулевого временем простоя на AWS и других ресурсах, посетите .
Также читайте другие статьи в нашем блоге:
Источник: habr.com
